The BASIC dialect we're using here is derived from Tom Pittman's, and it uses an interpreted bytecode called TBIL to do most of the work of interpreting BASIC.
As I think I mentioned elsewhere, I made a TBIL code generator for the asl assembler and successfully rebuilt the TBIL code.
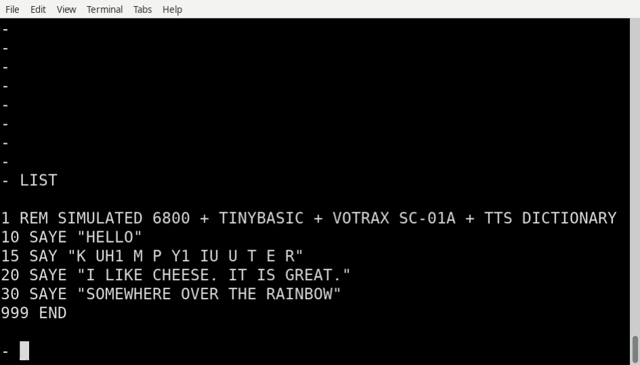
Now, this bears fruit: It made it say to add the SAY command. A few posts above, I was sending phoneme numbers as numbers.
But now, I wrote a program that turns the phoneme list into a series of TBIL parsing instructions, so that you can write
10 SAY "HE H3 L L O"
20 SAY"K UH1 M P Y1 IU U T E R"
30 END
Comma and period are used for the two pause
codes, rather than PA0 and PA1.
It takes about 450 bytes of (ROM) code to parse the phonemes.
I've been using this phoneme dictionary to look up words:
doing English to phoneme translation would be Much Harder (TM)