Jun 22, 2026, 6:20 PM
Jun 22, 2026, 6:20 PMBuild a fully local voice assistant in 2026
A practical setup for a Raspberry Pi-friendly voice assistant based on Platypush.
Those who have followed me for a while know of my personal obsession with self-built voice assistants.
My experiments over the years can be summarized as it follows:
-
2007: Voxifera, my very first attempt at building a primitive voice assistant using Hidden Markov models. Definitely not good for general-purpose usage, but good enough in 2007 to distinguish between a dozen of simple voice commands.
-
2019: First voice assistant built on top of Platypush. It used the now deprecated Google Assistant Library on top of a Raspberry Pi with a microphone and a speaker, and it could hook any automation routines and custom commands to it through event hooks.
-
2020: Second iteration on #platypush, this time supporting other assistant plugins too - Alexa (integration now removed), Snowboy (also removed, since the project is dead), Mozilla DeepSpeech (also removed now, since Mozilla discontinued it), PicoVoice, and mimic3 (the text-to-speech engine built on top of Mycroft, now bankrupt).
-
2024: Third iteration on Platypush, this time with an enhanced PicoVoice integration and new speech-to-text and text-to-speech plugins based on the OpenAI APIs.
But it's now 2026, and perhaps both the hardware and the software are now mature enough for fully on-device voice assistants based on fully open solutions likely to stick around for a while.
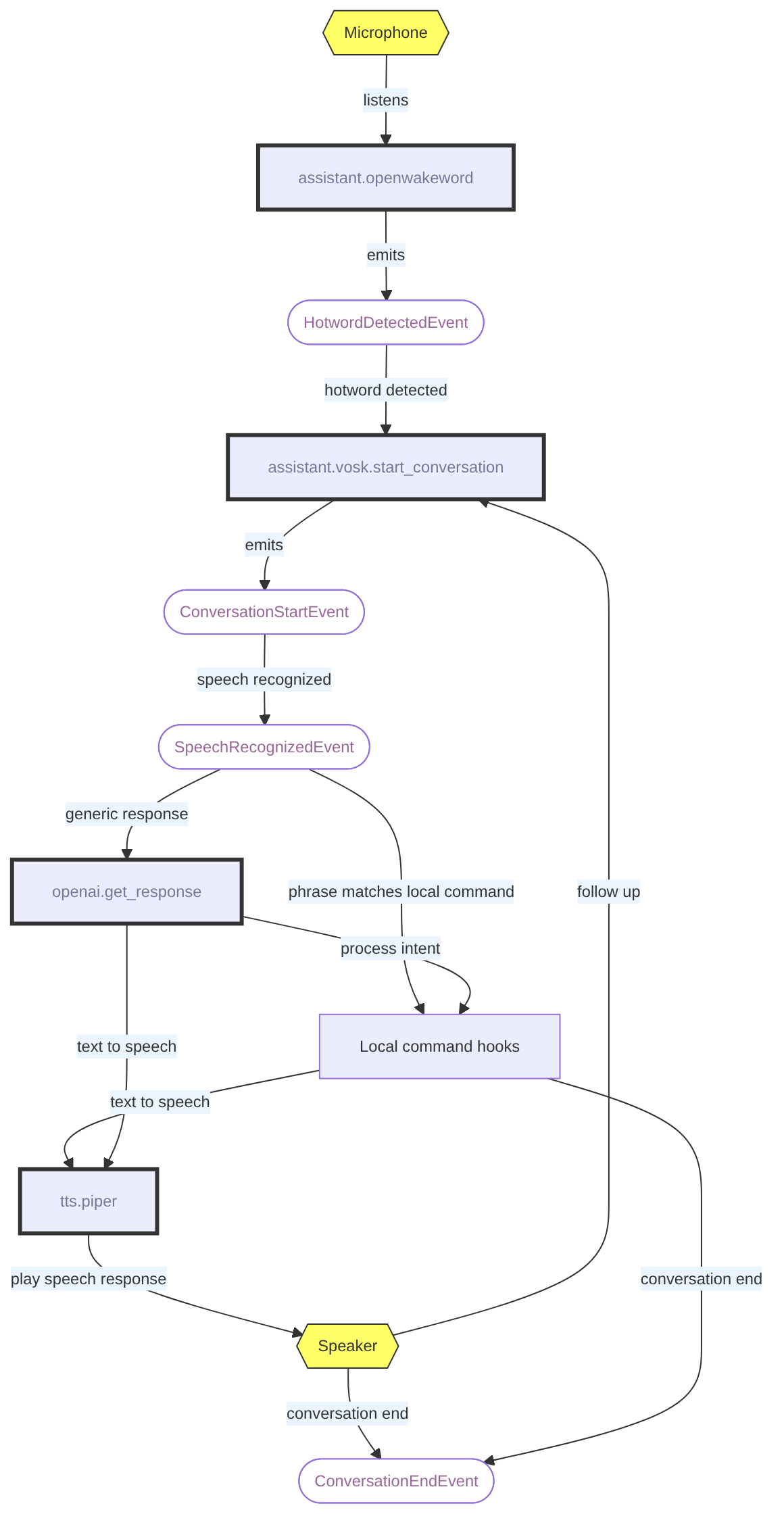
In this article we'll wire that gap closed with Platypush:
assistant.openwakewordlistens for the wake word locally.assistant.vosktranscribes the command locally.tts.piperspeaks the answer locally.openaiis used only where a language model is useful: turning messy speech into intent, or answering general questions.- Existing home automation plugins such as
light.hue,music.mpdorweather.openweathermapto provide the actions.
The result is not another cloud assistant with a different coat of paint. The hotword engine, speech recognition, command dispatch and speech synthesis can all run on-device. If the openai step points to a local OpenAI-compatible server, then the whole pipeline can stay on your LAN too.
The pipeline
The architecture can be summarized as follows:
Hotword detection ("OK Google", "Alexa" etc.) is a continuous, low-latency workload, and it should not need the network.
Speech-to-text is also a good fit for local inference: Vosk models are small enough to run on modest hardware, including Raspberry Pis, and they are perfectly adequate for short home automation commands.
Text-to-speech is another place where local models are good enough nowadays: Piper voices are fast, small and much nicer than the old robotic espeak-style fallback.
The only optional network-shaped piece is the language model.
But that is a policy choice, not a requirement of the voice stack.
Setup
Clone the assistant sample repository:
git clone https://git.platypush.tech/platypush/assistant-sample
cd assistant-sample
Models
The next step is to download the voice models used by the voice stack.
Hotword Detection
When the service starts the first time, it will automatically download all the available models.
You can then use the following command to list the available models once the service is running:
curl -s -XPOST \
-H 'Content-type: application/json' \
-H "Authorization: Bearer $PLATYPUSH_TOKEN" \
-d '{"type":"request", "action":"assistant.openwakeword.list_models"}' \
http://localhost:8008/execute
Where $PLATYPUSH_TOKEN is the token of the user that is running the service.
You can retrieve it by connecting to http://localhost:8008 when the service starts for the first time. Create your credentials, then select Settings -> Tokens -> Generate API Token.
Speech-to-text
A full list of the Vosk voice models is available here.
Some feedback about the quality of the English models:
Model Size Notesvosk-model-small-en-us-0.15
40 MB
Very fast and lightweight model that can also run on an old Raspberry Pi, but accuracy can be low.
vosk-model-en-us-0.22-lgraph
128 MB
Reasonably accurate on clear speech and with native speakers, but still small enough to run fine even on a Raspberry Pi.
vosk-model-en-us-0.22
1.8 GB
Accurate generic US English model. Fast on an laptop or x86 processor, but it may be a bit heavy on a Raspberry Pi.
Download the selected model to the Docker volume working directory:
mkdir -p ./workdir/assistant.vosk/models
cd ./workdir/assistant.vosk/models
wget "https://alphacephei.com/vosk/models/vosk-model-en-us-0.22-lgraph.zip"
unzip "vosk-model-en-us-0.22-lgraph.zip"
rm "vosk-model-en-us-0.22-lgraph.zip"
Text-to-speech
Download a speech synthesis model from here.
Audio samples are also available to get an idea of the type of voice before downloading.
The model usually consists of a *.onnx and a *.onnx.json file. Download both of them to the Docker volume working directory:
mkdir -p ./workdir/piper_tts
cd ./workdir/piper_tts
wget "https://huggingface.co/rhasspy/piper-voices/resolve/main/en/en_US/hfc_female/medium/en_US-hfc_female-medium.onnx"
wget "https://huggingface.co/rhasspy/piper-voices/resolve/main/en/en_US/hfc_female/medium/en_US-hfc_female-medium.onnx.json"
Configuration
Copy and edit the example configuration file.
cp config/config.example.yaml config/config.yaml
Home automation plugins
The assistant becomes useful once recognized speech can reach the rest of the house.
For example, Hue lights:
light.hue:
bridge: hue
groups:
- Living Room
And MPD/Mopidy for music:
music.mopidy:
host: localhost
music.mpd:
host: localhost
poll_interval: null
Those are just regular Platypush plugins.
The assistant does not need special knowledge about Hue, MPD, Chromecast, Zigbee, MQTT or anything else.
It only needs to emit events; your hooks decide what to do with them.
Build
Build the container image for the assistant service:
docker build -t platypush-voice .
Run
The assistant needs access to the host microphone and speakers. The container routes ALSA through PulseAudio, so the examples below connect it to a PulseAudio server running on the host.
Linux
With PulseAudio or pipewire-pulseaudio installed:
docker run --rm \
-e PULSE_SERVER=unix:/run/pulse/native \
-v /run/user/$(id -u)/pulse/native:/run/pulse/native \
--name voice-assistant \
-p 8008:8008 \
-v ./config:/etc/platypush \
-v ./workdir:/var/lib/platypush \
platypush-voice
macOS
Install and start PulseAudio on the host:
brew install pulseaudio
pulseaudio --daemonize=yes --exit-idle-time=-1
pactl load-module module-native-protocol-tcp \
auth-anonymous=1 \
listen=0.0.0.0 \
port=4713
Then start the container:
docker run --rm \
-e PULSE_SERVER=tcp:host.docker.internal:4713 \
--name voice-assistant \
-p 8008:8008 \
-v "$(pwd)/config:/etc/platypush" \
-v "$(pwd)/workdir:/var/lib/platypush" \
platypush-voice
If pactl load-module reports that the module is already loaded, you can keep using the existing PulseAudio daemon.
Windows
Install PulseAudio for Windows, then create a default.pa file in the same directory as pulseaudio.exe:
load-module module-waveout sink_name=output source_name=input record=1
load-module module-native-protocol-tcp auth-anonymous=1 listen=0.0.0.0 port=4713
set-default-sink output
set-default-source input
Start PulseAudio from PowerShell:
.\pulseaudio.exe -F .\default.pa --exit-idle-time=-1
Then start the container from the repository directory:
docker run --rm `
-e PULSE_SERVER=tcp:host.docker.internal:4713 `
--name voice-assistant `
-p 8008:8008 `
-v "${PWD}/config:/etc/platypush" `
-v "${PWD}/workdir:/var/lib/platypush" `
platypush-voice
Make sure microphone access is enabled for desktop applications under Windows privacy settings, and allow PulseAudio through the firewall if prompted.
Usage
Once the service is running, you can start interact with it with voice commands (the default activation word is "Alexa").
Any questions about the weather will be resolved by the weather plugin if it's been enabled.
If the music or lights plugins are enabled, they can be controlled with voice commands ("stop the music", "turn on the lights", etc.)
Otherwise, the assistant will use the openai plugin to respond to your questions, with follow-up turns when the response from OpenAI is also a question.
Extending the Assistant
The assistant logic is modeled through simple Platypush hooks under config/scripts.
You can extend it as you like by defining your own hooks or modifying the existing ones.
Starting a conversation
Conversations are started by hooking to the HotwordDetectedEvent.
import logging
from platypush import run, when
from platypush.events.assistant import HotwordDetectedEvent
logger = logging.getLogger(__name__)
ai_plugin = "openai"
assistant_plugin = "assistant.vosk"
@when(HotwordDetectedEvent)
def on_hotword_detected(event: HotwordDetectedEvent):
"""
When the hotword is detected, start a conversation.
"""
logger.info(f"Hotword {event.hotword} detected")
run(f"{assistant_plugin}.start_conversation")
Deterministic commands
For common home automation commands, regular event hooks are still the best tool. They are fast, inspectable, and they do not hallucinate.
from platypush import run, when
from platypush.events.assistant import SpeechRecognizedEvent
@when(SpeechRecognizedEvent, phrase="turn on (the)? lights")
def turn_on_lights():
"""
Hook run when the user says "turn on the lights" (regex)
"""
run("light.hue.on")
@when(SpeechRecognizedEvent, phrase="play (the)? music")
def play_music():
"""
Hook run when the user says "play the music" (regex)
"""
run("music.mpd.play")
@when(SpeechRecognizedEvent, phrase="set the music volume (to|on|at) ${volume}")
def set_volume(volume: int):
"""
Hook run when the user says "set the music volume to ${volume}"
(regex with parameter).
"""
run("music.mpd.set_volume", volume=volume)
AI Commands
If the openai plugin is enabled, you can use it to help you answer questions.
There are two generic use-cases for voice assistants where an AI plugin is beneficial:
- Speech to Intent
- Response fallback
Speech to Intent
You may want this for general questions, for commands that do not fit a neat regular expression, or for transforming a raw sentence such as:
make it a bit darker and reduce the music volume
into a structured action plan like.
[
{
"action": "light.hue.set_lights",
"args": {
"bri": 50
}
},
{
"action": "music.mpd.set_volume",
"args": {
"volume": 20
}
}
]
An example provided in the assistant sample is that of weather forecasting.
Note in particular the usage of openai.get_response with a well crafted system prompt that turns a natural language request like:
What's the weather tomorrow in San Francisco?
Into:
{
"type": "weather",
"delta_days": 1,
"location": "San Francisco"
}
def parse_weather_request(request: str) -> WeatherRequest | None:
request_dict = (
run(
"openai.get_response",
context=[
{
"role": "system",
"content": (
"You are a voice assistant provided with weather requests as free text.\n"
"Given the prompt, return a structured JSON representation of the request in the following format: "
'{ "type": "weather", "delta_days": 1, "location": "San Francisco" }, '
'where both delta_days and location are optional (e.g. if the user simply asks "How\'s the weather?".\n'
'If the prompt doesn\'t seem to contain a weather request, return { "type": null }'
),
}
],
prompt=request,
)
or {}
)
if request_dict.get("type") != "weather":
return None
weather_request = WeatherRequest(
location=request_dict.get("location", default_location),
delta_days=request_dict.get("delta_days", 0),
)
return weather_request
You can also use the model for intermediate transformation instead of direct answers. For example, ask it to return a tiny JSON object with action and args, then dispatch only actions you explicitly allow:
ALLOWED_ACTIONS = {
"lights.on": "light.hue.on",
"lights.off": "light.hue.off",
"music.play": "music.mpd.play",
"music.stop": "music.mpd.stop",
}
@when(SpeechRecognizedEvent)
def on_fuzzy_command(event):
plan = run(
"openai.get_response",
prompt=event.phrase,
context=[
{
"role": "system",
"content": (
"Map the user command to JSON only: "
'{"action": "...", "args": {...}}. '
f"Allowed actions: {', '.join(ALLOWED_ACTIONS)}. "
"If none match, return {\"action\": null, \"args\": {}}."
),
}
],
)
# Parse `plan` as JSON here, validate it, then run only an allow-listed action.
That last validation step matters. A model may be useful for interpretation, but it should not get arbitrary access to run().
Response fallback
If a request doesn't match any of the commands you have defined, you can use a generic SpeechRecognizedEvent hook to forward the request to an AI plugin, and render the response as speech through the text-to-speech plugin.
import logging
from platypush import run, when
from platypush.events.assistant import SpeechRecognizedEvent
logger = logging.getLogger(__name__)
ai_plugin = "openai"
assistant_plugin = "assistant.vosk"
@when(SpeechRecognizedEvent, plugin=assistant_plugin)
def on_speech_recognized(event: SpeechRecognizedEvent):
"""
Generic handler for speech recognition events received
by the configured assistant plugin.
"""
logger.info("Recognized speech: %s", event.phrase)
# Forward the request to OpenAI and render the response as speech
response = run(
f"{ai_plugin}.get_response",
prompt=event.phrase,
context=[
{
"role": "system",
"content": (
"You are a voice assistant that can answer questions and perform actions. "
"Keep in mind that prompts are transcriptions of user speech and they may "
"contain misspellings or errors. Try and interpret them as best as possible. "
"When possible, keep your answers short and concise."
),
}
],
)
# If the response is not empty, render it using the TTS plugin
if response:
event.assistant.render_response(response)
When a response from the LLM ends with a question mark, the assistant will automatically listen for a follow-up command and fire a new SpeechRecognizedEvent.
Pausing music while listening
One nice touch is to pause the music when a conversation starts and resume it after the assistant is done.
from platypush import run, when
from platypush.events.assistant import (
ConversationEndEvent,
ConversationStartEvent,
)
@when(ConversationStartEvent)
def on_conversation_start(event):
run("music.mpd.pause_if_playing")
@when(ConversationEndEvent)
def on_conversation_end():
run(
"utils.set_timeout",
name="ConversationEndTimeout",
seconds=5,
actions=[{"action": "music.mpd.play_if_paused"}],
)
That makes the interaction feel much less clumsy: wake word, music ducks or pauses, command is recognized, answer is spoken, music resumes a few seconds later.
Going fully local
With the configuration above, hotword detection, speech-to-text, automation and text-to-speech are already local. The only non-local component is the openai plugin, if it points to OpenAI's servers.
To make the last step local too, run a model server that exposes an OpenAI-compatible API. Ollama, llama.cpp server, vLLM and LocalAI can all expose some version of /v1/chat/completions.
For example, with Ollama:
ollama pull llama3.1:8b
ollama serve
The OpenAI-compatible endpoint is then usually available at:
http://127.0.0.1:11434/v1/chat/completions
If your Platypush openai plugin version supports a custom API base URL, the configuration is the whole change:
openai:
model: llama3.1:8b
base_url: http://127.0.0.1:11434/v1
If it does not, keep the rest of the assistant exactly the same and replace only the fallback action with a tiny local request:
That is enough to turn the assistant into a fully local stack:
On a Raspberry Pi, I would still keep expectations realistic. Hotword detection, Vosk and Piper are fine on small machines. Local LLMs are the heavy piece. A Pi 5 with enough RAM can run small quantized models, but latency will not feel like a cloud model or a GPU-backed workstation. For many home automation workflows, that is acceptable because the LLM is only the fallback; the frequent commands stay deterministic.
Why this architecture ages well
Voice assistants have been a graveyard of abandoned SDKs and cloud products. Snowboy is gone. Mycroft is gone. The old Google Assistant SDK is deprecated. Vendor assistants are increasingly shaped around vendor ecosystems rather than user-controlled automation.
The safer long-term bet is not one monolithic assistant. It is a pipeline of small replaceable parts:
- Swap the hotword model without touching the automation logic.
- Swap Vosk for another STT engine without touching Hue or MPD.
- Swap OpenAI for a local OpenAI-compatible model without touching the wake word, TTS or command hooks.
- Swap Piper voices without touching the assistant flow.
Platypush is a good fit for this because its event system is already the boundary between perception and action. Speech recognition emits an event. Hooks decide what to do. Plugins execute the actions.
That separation is what makes the assistant inspectable. It is also what makes it possible to keep most of it on a Raspberry Pi in your house, instead of outsourcing the entire audio loop to a cloud service that may disappear, get worse, or decide one day that your use case is no longer part of the roadmap.
Final notes
The minimal version of this setup is small:
assistant.openwakewordfor the always-on wake word.assistant.voskfor local command transcription.- A few
@when(SpeechRecognizedEvent, phrase=...)hooks for deterministic commands. light.hue,music.mpdor any other Platypush plugin for actions.tts.piperfor local spoken responses.openai.get_responseonly where language understanding is worth the cost.
Start with the deterministic commands. Add the model fallback later. That way the assistant stays fast for the commands you use every day, while still being flexible enough to answer questions or interpret messy speech when you need it.